MySQL
Chapt.2 Select
1. Wildcard, regular expression, ORDER and LIMIT
SELECT *
FROM customers
-- WHERE (address LIKE '%trail%' OR address LIKE '%avenue%') AND phone LIKE '%4' # "%" is the early used wildcard
-- WHERE last_name REGEXP 'field|mac|rose' OR last_name REGEXP 'll$' OR last_name REGEXP '^boa' # Regular expression
WHERE last_name REGEXP '[gim]e' OR last_name REGEXP 'a[n-w]' # last_name that include "ge/ie/me/an-aw"
ORDER BY points DESC
LIMIT 3; # LIMIT must be placed in the end of snippet
SELECT first_name, last_name,
10 AS points # Give a value and name it with "points" (has no relation with the "points" column)
FROM customers
ORDER BY birth_date DESC; # Multiple columns can be set for one ordering
2. Null
SELECT *
FROM orders
WHERE shipped_date IS NULL;
Chapt.3 Join
1. Regular form of an inner join
SELECT *
FROM customers c # Cannot use its original name once the column has an alias
JOIN orders o
ON o.customer_id = c.customer_id
2. Joining across databases
SELECT *
FROM order_items oi
JOIN sql_inventory.products p
ON oi.product_id = p.product_id;
3. Self join
USE sql_hr;
SELECT e.employee_id, e.first_name, e.reports_to, m.first_name AS manager
FROM employees e
JOIN employees m # Self join, to find the manager
ON e.reports_to = m.employee_id;
4. Outer join
- The inner join only returns content that meets the join conditions, causing some content to be lost. To display these lost content, an outer join is required (left/right)
USE sql_invoicing;
SELECT *
FROM clients c
LEFT JOIN payments p
USING (client_id) # If the column names are the same, use USING instead of ON
LEFT JOIN payment_methods pm # Join multiple tables
ON p.payment_method = pm.payment_method_id
LEFT JOIN invoices i
ON c.client_id = i.client_id # Compound Join Conditions
AND p.invoice_id = i.invoice_id # In this case, the second condition is actually an inner join!!
ORDER BY c.client_id;
5. Union
- With UNION, each query must contain the same columns, expressions and aggregation functions
- This snippet is optimized in Chapt 7
SELECT customer_id, first_name, points, 'Bronze' AS type
FROM customers
WHERE points<2000
UNION
SELECT customer_id, first_name, points, 'Silver' AS type
FROM customers
WHERE points BETWEEN 2000 AND 3000
UNION
SELECT customer_id, first_name, points, 'Gold' AS type
FROM customers
WHERE points>3000
ORDER BY first_name;
Chapt.4 Column Operation
1. Insert
INSERT INTO customers
VALUE(
DEFAULT, # The customer_id column is Auto Incremental, use "last_insert_id()" to get the id of last insert
'John',
'Smith',
'1998-07-15',
DEFAULT,
'8 Xinhui Road',
'Chengdu',
'CN',
9980
),
( # Insert multiple rows
DEFAULT,
'Michael',
'Jackson',
'1978-12-15',
DEFAULT,
'1 Star Avenue',
'Los Angeles',
'US',
9999
);
2. Delete
- Difference between DELETE, TRUNCATE and DROP:
TRUNCATE and DELETE only delete data without deleting the structure of the table; DROP will delete the structure of the table, triggers, indexes, etc
DELETE FROM customers # Delete all the columns, but can be filtered by WHERE
WHERE first_name = 'Michael' AND last_name = 'Jackson';
3. Copy a table
USE sql_invoicing;
CREATE TABLE invoices_archived AS
SELECT i.invoice_id, i.number, c.name AS client, i.invoice_total, i.payment_total, i.invoice_date, i.due_date, i.payment_date
FROM invoices i
JOIN clients c USING (client_id)
WHERE payment_date IS NOT NULL;
4. Update
UPDATE invoices
SET # Becasue sql doesn't have "==", we must use SET to change values
payment_total = invoice_total/2,
payment_date = due_date
-- WHERE client_id IN (3,5) # Update multiple columns
WHERE client_id = ( # If the result of nested query is not unique, change "=" to "IN" here
SELECT client_id
FROM clients
WHERE name='Myworks'
);
Chapt.5 Aggregation Function
1. Common AFs
USE sql_invoicing;
SELECT
MAX(invoice_total) AS highest,
MIN(invoice_total) AS lowest,
AVG(invoice_total) AS average,
SUM(invoice_total) AS total,
COUNT(invoice_total) AS number, # COUNT only counts for non-NUll
COUNT(DISTINCT client_id) AS client_number # DISTINCT for deduplication
FROM invoices;
2. GROUP BY
- Only useful for aggregation functions!
SELECT
p.date,
pm.name AS payment_method,
SUM(p.amount) AS total_payments
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY p.date, pm.name # Each group is a combination of these 2 columns
3. HAVING
- Filtering with HAVING after GROUP BY, and can only filter contents exist in SELECT
USE sql_store;
SELECT
c.customer_id, c.first_name, c.last_name, c.state,
SUM(oi.quantity*oi.unit_price) AS spent_money
FROM customers c
JOIN orders o USING(customer_id)
JOIN order_items oi USING(order_id)
WHERE state='VA' # WHERE must be written before GROUP BY
GROUP BY c.customer_id, c.first_name, c.last_name, c.state
HAVING spent_money>100;
Chapt.6 Complex Query
1. Subquery example
USE sql_invoicing;
SELECT *
FROM clients
WHERE client_id NOT IN (
SELECT DISTINCT client_id
FROM invoices
);
Another style with JOIN
SELECT *
FROM clients
LEFT JOIN invoices USING(client_id)
WHERE invoice_id IS NULL;
Another style with EXISTS
SELECT *
FROM clients c
WHERE NOT EXISTS (
SELECT client_id
FROM invoices
WHERE client_id = c.client_id
);
2. Correlated subquery
SELECT *
FROM invoices i
WHERE invoice_total > (
SELECT AVG(invoice_total)
FROM invoices
WHERE client_id = i.client_id #
);
3. FROM & SELECT subquery
SELECT *
FROM ( # FROM subquery. Only for single queries!
SELECT
invoice_id,
invoice_total,
(SELECT AVG(invoice_total) # SELECT subquery. Direct using "AVG(invoice_total)" returns only 1 row
FROM invoices) AS invoices_avg,
invoice_total - (SELECT invoices_avg) AS difference
FROM invoices
) AS invoice_summary; # Must have alias
Chapt.7 Built-in Function
1. Number
SELECT ROUND(3.1415926, 4);
SELECT TRUNCATE(4.24923, 2);
SELECT CEILING(5.2); # Minimal integer >= input
SELECT FLOOR(5.2); # Maximal integer <= input
SELECT RAND(); # Random in (0,1)
2. String
SELECT TRIM(' A-928 201 24 '); # Remove leading and trailing spaces
SELECT SUBSTRING('Kindergarten', 2, 4); # Extract 4 characters, start with character No.2 (1,2,3,...)
SELECT LOCATE('der', 'Kindergarten');
SELECT REPLACE('Kindergarten', 'e', 'de');
SELECT CONCAT('Zheng', ' ', 'Zhongyi');
3. Time
SELECT *
FROM orders
WHERE YEAR(order_date) = EXTRACT(YEAR FROM NOW());
SELECT DATEDIFF(NOW(), '1998-07-15');
4. IFNULL & COALESCE & IF
SELECT
order_id,
order_date,
-- IFNULL(shipper_id, 'Not assigned') AS shipper, # If the first parameter is NULL, return the second one
COALESCE(shipper_id, comments, 'Not assigned') AS shipper, # Replace NULL with the first non-NULL parameter
IF(YEAR(order_date) = 2019, 'Active', 'Archive') AS status
FROM orders;
5. CASE
SELECT
order_id,
order_date,
CASE
WHEN YEAR(order_date)=2019 THEN 'Active'
WHEN YEAR(order_date)=2018 THEN 'Last year'
WHEN YEAR(order_date)<2018 THEN 'Archived'
ELSE 'Future'
END AS status
FROM orders;
Optimize the last snippet in Chapt 3
SELECT
customer_id, first_name, points,
CASE
WHEN points<2000 THEN 'Bronze'
WHEN points BETWEEN 2000 AND 3000 THEN 'Silver'
WHEN points>3000 THEN 'Gold'
END AS type
FROM customers
ORDER BY first_name;
Chapt.8 View
1. Create view
- Treat view as a snapshot of the query result of a table
USE sql_invoicing;
CREATE VIEW sales_by_client AS
SELECT
c.client_id,
c.name,
SUM(invoice_total) AS total_sales
FROM clients c
JOIN invoices i USING (client_id)
GROUP BY c.client_id, c.name;
2. Delete view
DROP VIEW IF EXISTS sales_by_client;
3. Updatable view
- View without DSTINCT, AF(GROUP BY, HAVING) and UNION can be used in UPDATE, INSERT and DELETE statements
- Used in case you don’t have direct access to a table
CREATE OR REPLACE VIEW invoice_with_balance AS
SELECT
invoice_id,
number,
client_id,
invoice_total,
payment_total,
invoice_total - payment_total AS balance,
invoice_date,
due_date,
payment_date
FROM invoices
WHERE invoice_total - payment_total > 0
WITH CHECK OPTION; # Prevent some unexpected missing of values
DELETE FROM invoice_with_balance
WHERE invoice_id = 1;
Chapt.9 Stored Procedure
1. Define a temp delimiter
- To avoid doing this, right click the “Stored Procedures” in the left navigator to create a SP
DELIMITER $$
2. Create SP
- Treat SP as a storage of the query process of a table
DELIMITER $$
CREATE PROCEDURE get_clients()
BEGIN
SELECT * FROM clients;
END$$
DELIMITER ;
3. Delete SP
DROP PROCEDURE IF EXISTS get_clients;
4. SP with parameters
DELIMITER $$
CREATE PROCEDURE get_unpaid_invoices_for_client(
client_id INT,
OUT invoices_count INT, # OUT means this parameter is used for output(try not to use it...)
OUT invoices_total DECIMAL(9,2) # 2 bits to store decimal, and the rest 7 to store integer
)
BEGIN
SELECT COUNT(*), SUM(invoice_total)
INTO invoices_count, invoices_total
FROM invoices i
WHERE i.client_id = client_id AND payment_total = 0;
END$$
DELIMITER ;
5. Variables in SP
DELIMITER $$
CREATE PROCEDURE get_risk_factor()
BEGIN
DECLARE risk_factor DECIMAL(9,2) DEFAULT 0; # Declare a variable, must write before SELECT sentences
DECLARE invoices_total DECIMAL(9,2);
DECLARE invoices_count INT;
SELECT COUNT(*), SUM(invoice_total)
INTO invoices_count, invoices_total
FROM invoices;
SET risk_factor = invoices_total / invoices_count * 5;
SELECT IFNULL(risk_factor, 0);
END$$
DELIMITER ;
Chapt.10 Trigger
1. Create trigger
- Trigger is automatically executed BEFORE or AFTER the INSERT, DELETE and UPDATE
DELIMITER $$
CREATE TRIGGER payments_after_insert # The INSERT trigger
AFTER INSERT ON payments
FOR EACH ROW
BEGIN
UPDATE invoices
SET payment_total = payment_total + NEW.amount
WHERE invoice_id = NEW.invoice_id;
END$$
INSERT INTO payments
VALUES(DEFAULT, 5, 3, '2019-01-01', 10, 1)$$
CREATE TRIGGER payments_after_delete # The DELETE trigger
AFTER DELETE ON payments
FOR EACH ROW
BEGIN
UPDATE invoices
SET payment_total = payment_total - OLD.amount
WHERE invoice_id = OLD.invoice_id;
END$$
DELETE FROM payments
WHERE payment_id > 8$$
DELIMITER ;
2. Delete trigger
DROP TRIGGER IF EXISTS payments_after_delete;
3. Show trigger
SHOW TRIGGERS;
4. Create Event
- Event is automatically executed according to a SCHEDULE
DELIMITER $$
CREATE EVENT yearly_delete_stale_audit_rows # Create an event to yearly delete data of previous years
ON SCHEDULE
EVERY 1 YEAR STARTS '2019-01-01' ENDS '2029-01-01'
DO
BEGIN
DELETE FROM payments
WHERE date < NOW() - INTERVAL 1 YEAR;
END$$
DELIMITER ;
5. Alter event
ALTER EVENT yearly_delete_stale_audit_rows DISABLE;
Chapt.11 Transaction
1. ACID features
- Atomicity: All changes to data are performed as if they are a single operation. That is, all the changes are performed, or none of them are
- Consistency: Data is in a consistent state when a transaction starts and when it ends
- Isolation: The intermediate state of a transaction is invisible to other transactions. As a result, transactions that run concurrently appear to be serialized
- Durability: After a transaction successfully completes, changes to data persist and are not undone, even in the event of a system failure
2. Create transaction
- MySQL uses autocommit mode by default, if you don’t explicitly use START TRANSACTION to start a transaction, each query will be treated as a transaction and automatically committed
START TRANSACTION; # Actually this sentence and the COMMIT are not necessary
UPDATE customers
SET points = points + 10
WHERE customer_id = 1;
COMMIT; # Changes only take effect after the commit, otherwise they would be rollbacked
3. Isolation level
- Use “lock” to prevent multiple transactions update the same content at the same time (cause lost update)
- 4 levels are set to cope with 4 kinds of concurrency issues:

SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
START TRANSACTION; # Non-repeatable reads
SELECT points FROM customers WHERE customer_id = 1;
SELECT points FROM customers WHERE customer_id = 1;
COMMIT;
4. Deadlock
- If 2 transactions are updating 2 records in a reverse order, it is likely to have deadlock
Chapt.12 Design A Database
1. ER Diagram
- Entity-Relationship has 3 components: entities, attributes, and relationships, which are used for conceptual design of relational databases
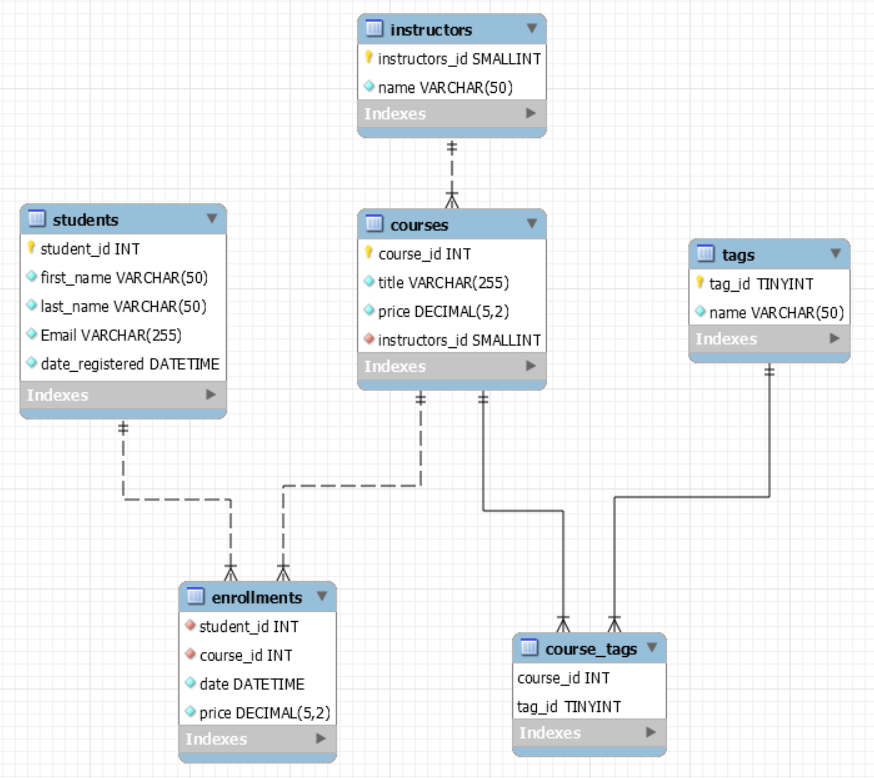
2. Normalization
- 1NF: A table cannot have repeated columns and each cell of it should have a single value
- 2NF: One table with its columns should represent only one entity
- 3NF: A column in a table should not be derived from other columns
- Tips1: Directly combine tables that are frequently joined together
- Tips2: Use 2 one-many relationships to represent the many-many relationship
3. Create database
CREATE DATABASE IF NOT EXISTS sql_store2;
USE sql_store2;
4. Create & Delete table
DROP TABLE IF EXISTS orders; # Because "orders" depends on "customers", we have to drop "orders" first
DROP TABLE IF EXISTS customers;
CREATE TABLE IF NOT EXISTS customers(
customer_id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
points INT NOT NULL DEFAULT 0,
email VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE IF NOT EXISTS orders(
order_id INT PRIMARY KEY,
customer_id INT NOT NULL,
FOREIGN KEY fk_orders_customers (customer_id)
REFERENCES customers (customer_id)
ON UPDATE CASCADE
ON DELETE NO ACTION
);
5. Alter table
ALTER TABLE customers
ADD last_name VARCHAR(50) NOT NULL AFTER first_name,
ADD city VARCHAR(50) NOT NULL,
MODIFY first_name VARCHAR(50) DEFAULT '',
DROP points;
-- DROP PRIMARY KEY; # Don't need to specify column name
6. Engine
SHOW ENGINES; # Store engines: InnoDB & MyISAM
Chapt.13 Indexing
1. Create index
- Design indexes based on the queries but not tables
- BTree: A type of index structure
CREATE INDEX idx_points ON customers(points);
EXPLAIN SELECT customer_id FROM customers
-- USE INDEX (idx_customers) # Not required
WHERE points > 1000; # rows: 1010 -> 529
2. Delete index
DROP INDEX idx_points ON customers;
3. Prefix indexes
- Only for BLOB, TEXT and VARCHAR
CREATE INDEX idx_lastname ON customers(last_name(20));
SELECT COUNT(DISTINCT LEFT(last_name, 1)),
COUNT(DISTINCT LEFT(last_name, 5)), # Best prefix index value
COUNT(DISTINCT LEFT(last_name, 10))
FROM customers;
4. Fulltext indexes
CREATE FULLTEXT INDEX idx_title_body ON posts(title, body);
SELECT *-- , MATCH(title, body) AGAINST ('javascript') AS scores
FROM posts
WHERE MATCH(title, body) AGAINST ('javascript') OR
MATCH(title, body) AGAINST ('"handling a form"' IN BOOLEAN MODE) OR
MATCH(title, body) AGAINST ('redux -react' IN BOOLEAN MODE);
5. Composite indexes
- Put index columns with higher selectivity first
Selectivity: unique index values/amount of records. The maximum value is 1, at which point each record has a unique index
CREATE INDEX idx_state_points ON customers(state, points);
EXPLAIN SELECT customer_id FROM customers WHERE state = 'CA' AND points > 1000;
- If we change the above AND to OR, indexes will be ignored, Mysql has to do a full index scan with 1010 rows
EXPLAIN SELECT customer_id FROM customers WHERE state = 'CA' # Split OR by UNION
UNION SELECT customer_id FROM customers WHERE points > 1000; # Both queries use the "idx_state_points" which means this index is a covering index
Chapt.14 Securing Database
1. Create user
CREATE USER moon_app IDENTIFIED BY 'admin';
2. Delete user
DROP USER moon_app;
3. Grant privilege
GRANT SELECT, INSERT, UPDATE, EXECUTE, DELETE, CREATE VIEW
ON sql_store.*
TO moon_app;
SHOW GRANTS FOR moon_app;
REVOKE CREATE VIEW
ON sql_store.*
FROM moon_app;